Contents
Introduction
12 April 2023
The end goal for me is to take my shopping list from Alexa, and turn this into a sorted list. However I quickly realized that it was quite a jump from my current level, thus i first need to step back and work on the basics.
So this form this basics, where I want to use python to scrape some websites to get usable data.
Lets explore this
The target for my search will be a jobsite, “https://jobserve.com” where we will look to pull down the latest jobs that have the keywords “cisco & python” in the last day.
For ease of keyword passing, ill just edit the online form and take a copy of the search ID “https://jobserve.com/gb/en/JobListing.aspx?shid=21D212D39D80605C8A02”
Tools and techniques used
So after some tinkering with various recommendation on stack exchange, I had the most success with the selenium package, in particular this was the base function:
##The required imports for this blog, added here so no need repeat.
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
def live_scrape():
###Set chrome to run headless, I do still see it launch/close in the mac taskbar.
chrome_options = Options()
chrome_options.add_argument("--headless")
###If the drvier for chrome not instaleld, it will go and get it.
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
###Tells teh chrome driver to get the content form the url
driver.get("https://jobserve.com/gb/en/JobListing.aspx?shid=21D212D39D80605C8A02")
html = driver.page_source
driver.quit()
return html
html = live_scrape()
##Lets dump the output to a text file for ease of investigation.
with open('data.txt', 'w+') as f:
for line in html:
f.write(line)
Now this did not work, and using my stare and compare approach i finally spotted the issue, here is how I got there:
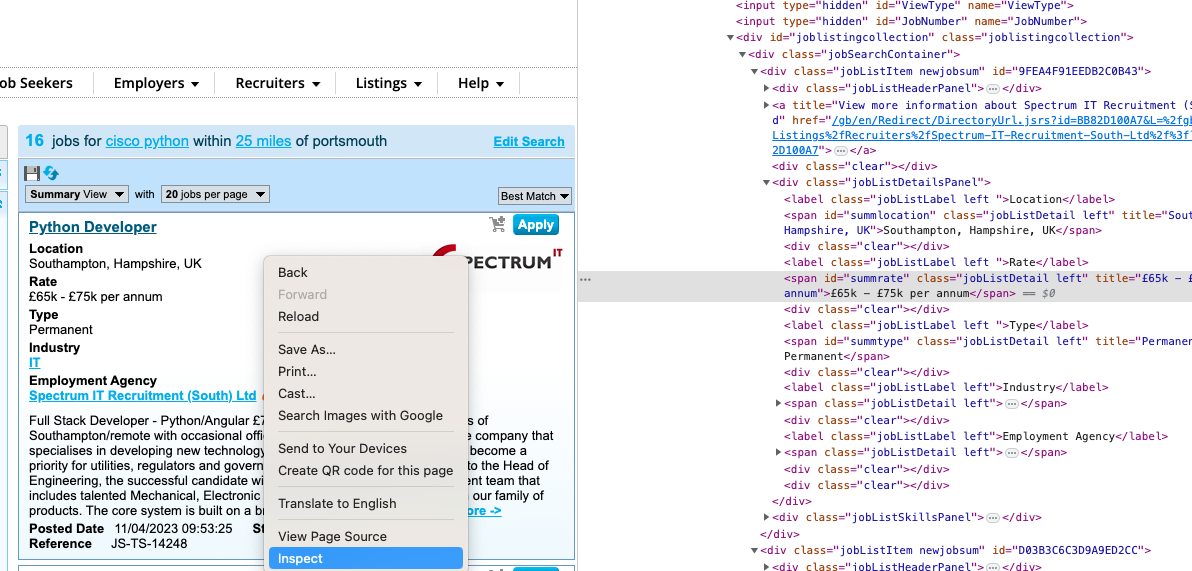
- First by the power of chrome developer tools we can find the data we want to use and work back from there:
So in the developer tools, if we inspect one of the job elements we can see the structure to the page. Where all jobs are nested under the classjobSearchContainer and within that calss there are muliple classes of jobListItem newjobsum each with all the various attributes we need.
 )
)
If we delve now into the HTML we pulled from our function, we have no data for these jobs, and no precece of hte jobSearchContainer. We see two levles above this class, the jobdisplaypanel, but then it jumps right down to the page summary.
<div id="jobdisplaypanel" class="ubpanel">
<div id="application"></div>
<div id="job"></div>
<div id="nojobsdiv"></div>
</div>
</div>
<div class="ui-layout-west jsborderpadoveride ui-layout-pane ui-layout-pane-west" style="display: block; position: absolute; margin: 0px; inset: 0px auto 0px 0px; height: 388px; z-index: 0; width: 210px; visibility: visible;" id="westpanel">
<div>
<div class="summary">
<div class="summary-top">
So it looks like this container we need is loaded into the page after the initial page load, so lets fix that. All we need to do is add in wait timer to check our hypothesis, however I know this will work and it’s not great to have a hardcoded timer, as the results may be fast! They may be slow… So I added a wait timer in a try block, this is from the selenium module that waits until i sees one of the elements jobResultsSalary is loaded thats nested in the ```jobSearchContainer`` class.
def live_scrape():
###Set chrome to run headless, I do still see it launch/close in the mac taskbar.
chrome_options = Options()
chrome_options.add_argument("--headless")
###If the drvier for chrome not instaleld, it will go and get it.
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
###Tells teh chrome driver to get the content form the url
driver.get("https://jobserve.com/gb/en/JobListing.aspx?shid=21D212D39D80605C8A02")
###The results take some time to load, so this tr block waits 30, or untill
###the jobs are loaded, this is check via the precence of class "jobResultsSalary"
try:
elem = WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.CLASS_NAME, "jobResultsSalary")))
###Once loaded pass the source HTML into variable
html = driver.page_source
finally:
driver.quit()
return html
##Lets dump the output to a text file for ease of investigation.
with open('data.txt', 'w+') as f:
for line in html:
f.write(line)
Now if we look into the retruned html, we can see the job listings are present!
<div class="summary-content">
<div id="jobreslist_outercontainer">
<div class="customScrollBox">
<div class="jsCustomScrollContainer" style="top: 0px;">
<div class="jsCustomScrollContent" id="jsJobResContent">
<div class="jobItem" id="9FEA4F91EEDB2C0B43"><div class="jobsum newjobsum jobSelected"><img src="https://az274887.vo.msecnd.net/images/blank.gif" class="right" height="16" width="10"><h3 class="jobResultsTitle">Python Developer</h3><p class="jobResultsSalary">£65k - £75k per annum</p><p class="jobResultsLoc">Southampton, Hampshire</p><p class="jobResultsType">Permanent</p><p class="when">1 day ago</p></div></div><div class="jobItem" id="D03B3C6C3D9A9ED2CC"><div class="jobsum newjobsum"><img src="https://az274887.vo.msecnd.net/images/blank.gif" class="right" height="16" width="10"><h3 class="jobResultsTitle">Network Engineer - CCNP</h3><p class="jobResultsSalary">
...
omitted
...
</div>
</div>
Now all wee need to do it tidy that data up and make it presentable, for this I used BeautifulSoupto nest the data in a more structured way, then parse the results in a for loop.
We look to see if it was posted in the last day (this is based on the ‘When” class stating hours and not days), then we pull out the jonb title and salary based on the tags.
html = live_scrape()
###Use BS4 to create a nested data structure
soup = BeautifulSoup(html, 'html.parser')
##Check and return only latest jobs
for j in soup.find_all('div', class_ ="jobItem"):
if 'hours' in j.find(class_='when').text:
print(j.find(class_='jobResultsTitle').text, end=' ')
salary = (j.find(class_='jobResultsSalary').text)
if len(salary) == 0:
print('No salary declared')
else:
print(salary)
Results:
Network Architect £600 - £700 per day
Network Engineer £400 - £500 per day
Network Engineer £35k - £45k per annum + Benefits package
A Senior Data Engineer - Southampton based £75k + bonus and benefits
Developer £40k - £50k
Network Engineer No salary declared
Infrastructure Engineer - Networks £550 - £600 per day
3rd Line Network Engineer £30k - £35k per annum + Benefits package
Systems Mathematical & Simulation Modeller 40k - 60k Annual GBP
Senior Mechanical Process Engineer 55k - 65k Annual GBP
Full code
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
def live_scrape():
###Set chrome to run headless, i do stil see it launch/close in the mac taskbar.
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
driver.get("https://jobserve.com/gb/en/JobSearch.aspx?shid=21D212D39D80605C8A02")
###Pass to a try block
try:
WebDriverWait(driver, 30).until(EC.presence_of_element_located((By.CLASS_NAME, "jobResultsSalary")))
###Once loaded pass the source HTML into variable
html = driver.page_source
finally:
driver.quit()
return html
html = live_scrape()
###Use BS4 to create a nested data structure
soup = BeautifulSoup(html, 'html.parser')
##Check and return only latest jobs
for j in soup.find_all('div', class_ ="jobItem"):
if 'hours' in j.find(class_='when').text:
print(j.find(class_='jobResultsTitle').text, end=' ')
salary = (j.find(class_='jobResultsSalary').text)
if len(salary) == 0:
print('No salary declared')
else:
print(salary)